1. Introduction: The Strategic Inflection Point of Visual AI
The trajectory of artificial intelligence in the latter half of 2025 and the dawn of 2026 has been defined by a decisive shift from unimodal capabilities to deeply integrated, multimodal reasoning engines. The battle for supremacy in generative media has escalated beyond the preliminary skirmishes of 2023 and 2024, maturing into a high-stakes industrial confrontation between the incumbent titans: OpenAI and Google. This report offers an exhaustive analysis of the two defining models of this era: OpenAI's GPT Image 1.5 and Google's Nano Banana Pro (technically designated as Gemini 3 Pro Image).
The context of this release cycle is critical. Late 2025 was characterized by what industry observers and internal leaks have described as a "Code Red" environment within OpenAI. Following a period where Google’s DeepMind began to aggressively close the capability gap with its Gemini architecture, OpenAI found its dominance in the generative landscape—previously secured by the release of GPT-4 and DALL-E 3—under substantial threat. The "Code Red" memo, attributed to CEO Sam Altman, underscored the urgency of reclaiming the narrative and technical lead from Google’s surging momentum, particularly as Gemini began to capture significant market share with its multimodal integration.
The visual domain has emerged as the primary theater for this conflict. Image generation is no longer merely a creative novelty; it has become a critical "battlefront" for consumer engagement and commercial adoption. The release of Nano Banana Pro in November 2025, followed closely by GPT Image 1.5 in December 2025, represents a bifurcation in design philosophy. While Google has pursued a strategy of "native multimodality," embedding visual synthesis directly into the reasoning core of its massive Gemini 3 architecture to achieve photorealism and world-grounding, OpenAI has doubled down on "instruction adherence" and workflow velocity, aiming to solve the persistent friction of iterative editing that has plagued diffusion models since their inception.
This report dissects these distinct approaches, analyzing the models not just as isolated software artifacts, but as expressions of broader ecosystem strategies. We will explore the technical specifications, visual fidelity, reasoning capabilities, economic models, and sociotechnical impacts of these systems, providing a definitive guide for enterprise decision-makers and developers navigating the complex topography of modern generative AI.
2. The Cultural and Strategic Context of "Nano Banana"
To understand the market dynamics of 2026, one must first analyze the peculiar branding phenomenon of "Nano Banana." The name itself serves as a case study in the intersection of engineering culture, internet virality, and modern product marketing.
2.1. Origin and Viral Mechanics
The moniker "Nano Banana" originated from an internal placeholder within Google DeepMind. During a late-night submission window for the LMSYS Chatbot Arena—a crowdsourced benchmarking platform that acts as a clearinghouse for model evaluation—the development team required an anonymous codename to prevent bias during blind testing. According to David Sherron, Google Gemini’s multimodal lead, and Product Manager Naina Raisinghani, the name was coined spontaneously at 2:00 AM. The logic was deceptively simple: "Nano" implied efficiency and compact power (despite the model's massive capabilities), while "Banana" was chosen for its distinctiveness, universal recognizability, and inherent playfulness.
The intent was anonymity, but the result was iconic branding. When the anonymous model began to dominate the leaderboards, outperforming existing benchmarks in image editing and fidelity, the community seized upon the eccentric name. The "Nano Banana" became a meme, trending on social platforms and SEO keywords long before Google officially confirmed the model's identity as Gemini 2.5 Flash Image and later Gemini 3 Pro Image.
2.2. Strategic Embrace of the Meme
Rather than enforcing corporate sterility, Google made the strategic decision to embrace the "Nano Banana" identity. This pivot was crucial for humanizing a company often perceived as monolithic and distant. The "banana" iconography—used in social media handles, watermarks, and even the "Generate Image" icon in the Gemini app (depicted as a half-peeled banana)—signaled a shift toward approachability.
This branding strategy addressed a core psychological barrier in AI adoption: intimidation. By associating state-of-the-art multimodal reasoning with a fruit emoji, Google lowered the perceived barrier to entry, inviting casual users to experiment with "chibi-style dioramas" and "miniature lamps," which became viral use cases. The cultural impact was tangible; the "Nano Banana" trend drove millions of users to the Gemini app, effectively acting as a trojan horse for the broader Gemini 3 ecosystem.
2.3. OpenAI’s Counter-Narrative
In stark contrast, OpenAI’s release of GPT Image 1.5 adhered to a strictly utilitarian nomenclature. The name reflects a lineage of software versioning (GPT-4, GPT-5, etc.), emphasizing iteration and professional reliability over cultural playfulness. The release was framed as a direct, feature-for-feature counter to Google’s momentum—a "salvo" in the ongoing war for dominance. While Google leveraged community virality, OpenAI leveraged its stronghold in the developer and enterprise consciousness, positioning GPT Image 1.5 as a "viable production asset" rather than a novelty. This divergence in branding mirrors the divergence in technical philosophy: Google courting the "prosumer" and creative crowd through culture, while OpenAI courted the developer and efficiency-focused user through precision.
3. Technical Architecture and Model Specifications
The performance differentials between the two models are rooted in fundamentally different architectural paradigms. Understanding these underpinnings is essential for evaluating their respective strengths and limitations.
3.1. Nano Banana Pro (Gemini 3 Pro Image)
Nano Banana Pro represents the culmination of Google’s "native multimodal" research. Unlike early systems that "bolted on" vision encoders to text models (e.g., CLIP guiding a diffusion U-Net), Nano Banana Pro is projected from the core Gemini 3 Pro architecture.
-
Unified Embedding Space: The model utilizes a sparse Mixture-of-Experts (MoE) Transformer architecture where visual, textual, and auditory tokens coexist in a unified embedding space. This allows the model to perform "deep reasoning" on visual concepts before a single pixel is generated. It plans the image semantically, understanding the physical relationships between objects (e.g., gravity, lighting, occlusion) as logical concepts rather than just statistical pixel correlations.
-
Search Grounding (RAG for Vision): A definitive technical advantage is the integration of Retrieval-Augmented Generation (RAG) via Google Search. The model can "ground" its visual generations in real-world data. If a user requests a diagram of a specific engine part or a map of a historical battle, Nano Banana Pro can retrieve current visual data to ensure accuracy, effectively solving the "hallucination" problem for factual imagery.
-
Context Window and Reference Fusion: Leveraging the massive context window of the Gemini 3 architecture (up to 1 million tokens), the model supports the simultaneous ingestion of up to 14 reference images. This capability acts as "few-shot prompting" for visual style, enabling the model to construct a "style guide" in real-time. It can maintain the identity of up to five distinct characters across different scenes—a feat that previously required complex LoRA (Low-Rank Adaptation) training in open-source models.
- Resolution and Output: The model supports native generation at 4K resolution (4096x4096) without reliance on secondary upscalers. This high-resolution capability is powered by Google’s TPU infrastructure, which is optimized for the massive matrix operations required by such large conceptual windows.

3.2. GPT Image 1.5
OpenAI’s GPT Image 1.5 appears to be a highly optimized evolution of the DALL-E 3 architecture, likely integrating a more sophisticated transformer-based diffusion pipeline that is tightly coupled with the GPT-4o reasoning layer.
-
Optimization for Latency: The defining architectural achievement of GPT Image 1.5 is speed. It creates images up to 4x faster than its predecessor. This reduction in latency is not merely a quality-of-life improvement; it transforms the utility of the model from a "batch process" (submit prompt, wait, review) to a "real-time conversation." This speed enables a tighter feedback loop, essential for the iterative editing workflow OpenAI is promoting.
-
Instruction Following and Logic: The model emphasizes "prompt adherence" over raw pixel resolution. OpenAI has tuned the model to strictly follow complex logical constraints, such as specific object placement in grids or the inclusion of disparate elements (e.g., specific text strings alongside visual objects) without "bleeding" concepts.
-
Editing Architecture: Unlike traditional diffusion in-painting, which often requires manual masking, GPT Image 1.5 utilizes a semantic editing engine. It interprets natural language "verbs" (add, subtract, blend) to modify specific tensors within the latent space without disrupting the global coherence of the image.
-
Resolution Constraints: Unlike the native 4K of Nano Banana Pro, GPT Image 1.5 optimizes for standard aspect ratios (Square 1:1, Portrait 2:3, Landscape 3:2) with resolutions generally capping around the 1-2 megapixel mark (e.g., 1024x1024 to 1024x1792). This reflects a prioritization of speed and accessibility over ultra-high-definition production.
3.3. Comparative Specifications Table
The following table summarizes the technical divergences between the two flagship models.
| Feature Specification | GPT Image 1.5 | Nano Banana Pro (Gemini 3 Pro Image) |
|---|---|---|
| Core Architecture | Optimized Diffusion / Transformer Hybrid | Native Multimodal MoE Transformer (Gemini 3) |
| Max Native Resolution | ~2 Megapixels (e.g., 1024x1792) | 4K (4096x4096) |
| | Aspect Ratio Support | Limited (1:1, 2:3, 3:2)
| Extensive (1:1, 4:3, 3:4, 16:9, 9:16, 21:9)
| | Reference Images | Support for likeness upload (limited context) | Up to 14 Reference Images (Style/Character Guide)
| | Generation Speed | High (4x faster)
| Moderate (Variable by "Thinking" mode)
| | Editing Paradigm | Conversational "Verbs" (Add/Subtract) | Masking, Multi-Image Blend, Global Parameter Control | | Watermarking | Standard Metadata | SynthID (Invisible & Robust to edits)
| | World Knowledge | Training Data Cutoff Dependent | Real-time Google Search Grounding
| | Character Consistency | Improved preservation of facial features | 5-Person Identity Preservation across scenes
|
4. Visual Fidelity and Aesthetic Performance
While architecture dictates capability, the ultimate test of a generative model is the subjective quality of its output. The rivalry between GPT Image 1.5 and Nano Banana Pro reveals a stark contrast in aesthetic philosophy: the "Platonic Ideal" vs. the "Cinematic Real."
4.1. Photorealism and the "Uncanny Valley"
A recurring theme in user analyses and technical reviews is the divergent approach to photorealism.
Nano Banana Pro: Google’s model has been lauded for its ability to traverse the "uncanny valley" and produce images that genuinely mimic the imperfections of optical photography. In blind tests conducted by user communities, Nano Banana Pro outputs are frequently indistinguishable from real photos because they include "flaws"—film grain, lens distortion, slight motion blur, and chaotic lighting scenarios.
- Case Study - The "Ford Mustang" Test: In a direct comparison where users generated images of a "fully black Ford Mustang parked in a dark road side," Nano Banana Pro produced an image that looked like a "casual photo snapped by a human." It captured the specific way dim streetlamp light diffuses on car paint, including the noise inherent in low-light photography. In contrast, the GPT Image 1.5 version looked like a "car commercial"—perfectly lit, glossy, and hyper-clean, revealing its synthetic nature.

- Texture Fidelity: Nano Banana Pro excels at high-frequency textures. It renders the pores of human skin, the chaotic weave of fabric, or the rust on metal with pixel-level accuracy. This is partly due to its 4K native resolution, which prevents the "smoothing" artifacts common in lower-res models.
GPT Image 1.5: OpenAI’s model tends toward a stylized, "studio" aesthetic. While it represents a massive leap over DALL-E 3, removing the "plastic" sheen that characterized earlier models, it still prioritizes aesthetic coherence over raw realism.
-
The "Glossy" Critique: Community feedback often describes GPT Image 1.5 outputs as "over-produced." Even when prompted for "amateur phone photography," the model often applies perfect compositional rules (Rule of Thirds, Golden Ratio) and ideal lighting, which paradoxically breaks the illusion of reality.
-
Style Emulation: However, GPT Image 1.5 shows strength in specific artistic emulations. In a test involving "1990s documentary street photography," it correctly applied the specific grain characteristics of Kodak Portra 400 film stock when explicitly prompted, demonstrating a deep understanding of artistic media even if its default bias is towards polish.
4.2. World Knowledge and Hallucination
The grounding of visual data is where Nano Banana Pro leverages Google’s search dominance.
-
Contextual Accuracy: In a test generating a scene in Amsterdam, Nano Banana Pro not only captured the visual vibe but included specific contextual details like "Dutch-looking subjects" and signage for an actual bar (though the specific terrace arrangement was hallucinated). This suggests the model is retrieving visual concepts from a knowledge graph rather than just generating generic "European city" pixels.
-
Scientific and Educational Diagrams: Nano Banana Pro is marketed heavily for its ability to generate accurate diagrams and infographics. By connecting to Google Search, it can generate a map or a biological diagram that respects factual anatomy and geography, whereas GPT Image 1.5 is limited to the generalized patterns in its training data, making it prone to "hallucinating" plausible but incorrect scientific details.
4.3. Text Rendering Capabilities
Text generation within images—a notorious failure mode for early GANs and diffusion models—has been a priority for both labs.
-
Nano Banana Pro: Claims "State-of-the-Art" (SOTA) text rendering. It supports multilingual text generation and complex layouts, such as wrapping text around cylindrical objects or placing it naturally in perspective on street signs. It is capable of generating entire infographics with legible paragraphs, a capability powered by the Gemini 3 text reasoning engine.
-
GPT Image 1.5: Has made significant strides in rendering dense text, numbers, and short phrases, making it viable for UI mockups and simple posters. However, benchmarks indicate it still lags behind Nano Banana Pro in long-form text consistency and non-English scripts. It creates "decently legible" text but struggles with complex typographic integration compared to Google’s engine.
5. Instruction Following, Reasoning, and Logic
The true utility of these models for developers and power users lies not just in image quality, but in "steerability"—the ability of the model to execute complex, multi-part instructions without error.
5.1. Complex Prompt Adherence
OpenAI has optimized GPT Image 1.5 specifically for logical adherence.
- The "Grid Test": In a rigorous benchmark involving a "6x6 grid" prompt requiring 36 distinct, unrelated objects (e.g., "a praying mantis," "the Greek letter beta," "a bathtub") to be placed in specific coordinates, GPT Image 1.5 successfully rendered the arrangement. This task requires the model to maintain 36 separate "attention heads" or distinct concept areas without allowing them to bleed into one another—a feat that typically causes diffusion models to fail.

- Logical Constraints: GPT Image 1.5 is reported to have a "90% compliance rate" on steerability benchmarks, making it superior for tasks where specific logical conditions must be met (e.g., "draw a red ball inside a blue box which is on top of a green pyramid").
Nano Banana Pro, while powerful, sometimes prioritizes the "vibe" or overall coherence of the image over strict logical adherence in complex spatial puzzles. However, it excels at "atmospheric logic"—understanding the nuances of a prompt like "1960s spy film" and applying the correct color grading, clothing, and architectural styles associated with that era.
5.2. Iterative Editing and Consistency
The ability to edit an image without breaking its consistency is the "Holy Grail" of generative media.
-
GPT Image 1.5 - The "Verb" Engine: OpenAI has introduced a set of semantic editing verbs: Add, Subtract, Combine, Blend, Transpose. This allows for a conversational workflow. A user can say, "Make the lighting colder," and the model adjusts the color temperature while rigidly preserving the facial structure and composition of the original generation. This addresses the "drift" problem where re-prompting a model usually results in a completely different random seed.
-
Nano Banana Pro - The "Composition" Engine: Google approaches consistency through asset fusion. By allowing up to 14 reference images, it enables a workflow where a user creates a "character sheet" and then places that character into new scenes. This is "consistency by design" rather than "consistency by editing." It allows for consistent branding across a campaign (e.g., the same mascot in 10 different poses) with higher fidelity than GPT’s conversational edits.
6. Integration and Ecosystem Strategy
The battle between OpenAI and Google is fundamentally a battle of ecosystems: Microsoft Foundry vs. Google Workspace.
6.1. Google Workspace and the "Productivity" Angle
Google has aggressively integrated Nano Banana Pro into its productivity suite.
- Google Slides: The model powers features like "Beautify this slide," where it can generate context-aware backgrounds or convert bullet points into professional infographics automatically.
-
Google Vids: In the video creation tool, Nano Banana Pro generates storyboards and assets that maintain consistency across a timeline, effectively serving as an asset generator for video production.
-
Enterprise Security: Google emphasizes "enterprise-grade" compliance, including copyright indemnification (at General Availability) and the invisible SynthID watermark, positioning the tool as safe for corporate legal departments.
6.2. Microsoft Foundry and the "Developer" Angle
GPT Image 1.5 is the flagship image model for Microsoft Foundry and Azure AI.
-
API-First Strategy: OpenAI’s primary focus is the API, enabling developers to build custom applications. The token-based pricing (discussed in Section 7) is designed to allow developers to build sophisticated "agentic" workflows where an AI agent might reason about an image, generate a draft, critique it, and edit it programmatically.
-
Marketing and E-commerce: Microsoft highlights the model’s ability to preserve branded logos and generate product catalogs (variants of a single product in different environments), targeting the massive e-commerce automation market.
7. Economics and Pricing Analysis
The divergence in pricing models significantly impacts the Return on Investment (ROI) for different user classes.
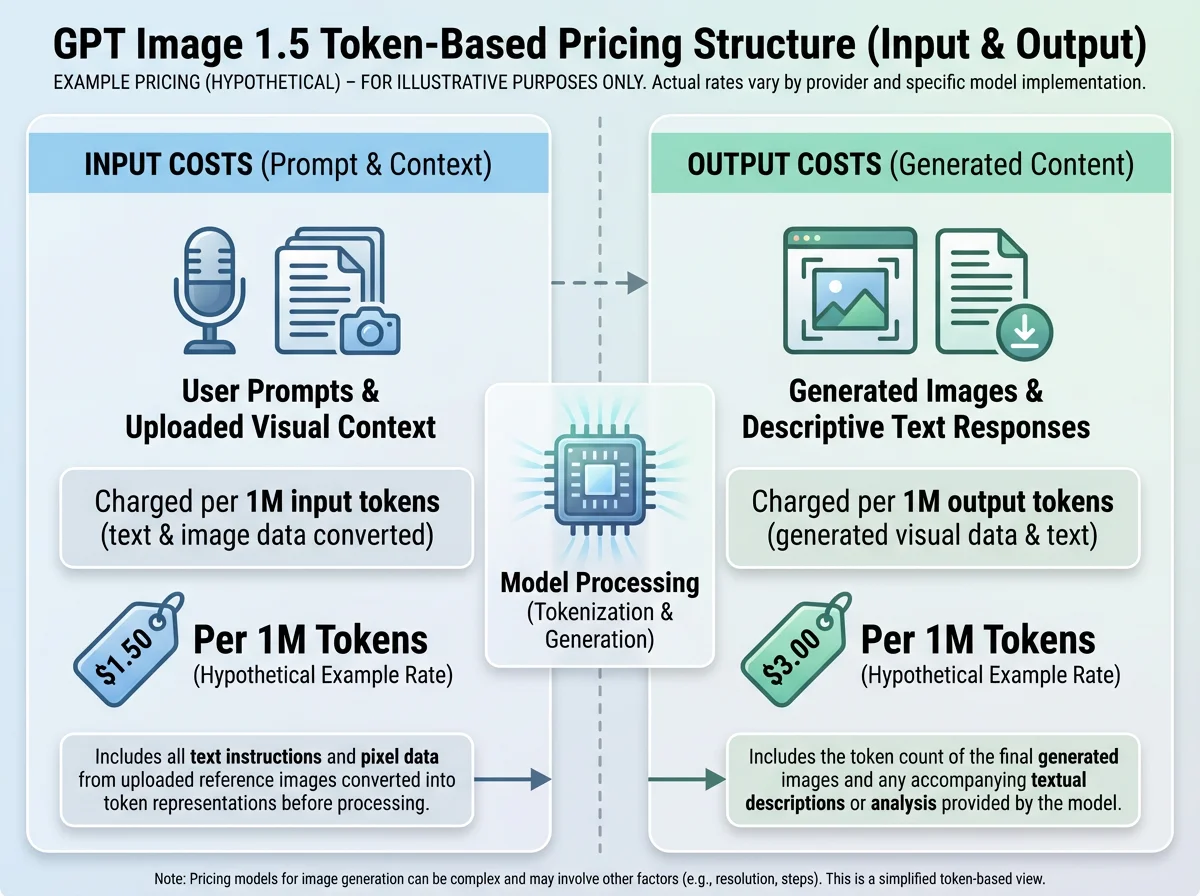
7.1. GPT Image 1.5: Token-Based Granularity
OpenAI has shifted to a token-based pricing model for GPT Image 1.5, moving away from the simple "per-image" flat rate of DALL-E 3.
-
Input Cost: ~$8.00 per 1 million tokens.
-
Output Cost: ~$32.00 per 1 million tokens.
-
Cached Inputs: Significant discounts ($1.25/$2.00) are offered for cached inputs, incentivizing repetitive workflows where the same context (e.g., a style guide or brand manual) is reused.
-
Cost Per Image: This structure makes the cost variable. A simple, low-resolution generation might cost significantly less than a complex, high-resolution output. OpenAI claims this results in a roughly 20% reduction in costs compared to GPT Image 1. Estimates place a standard high-quality generation between $0.04 and $0.17 depending on the "reasoning depth" required.
7.2. Nano Banana Pro: Throughput and Resolution
Google employs a pricing model based on resolution tiers and throughput.
-
Standard (1K/2K): ~$0.134 per image.
-
High-Res (4K): ~$0.24 per image.
-
Batch Processing: A significantly discounted "batch" tier (e.g., ~$0.067/image) allows enterprises to process massive queues of images asynchronously (e.g., generating 10,000 product variants overnight).
-
Subscription: For individual users, the Gemini Advanced subscription ($19.99/mo) offers essentially "unlimited" access to the model (subject to rate limits), creating a massive value surplus for heavy users compared to the pay-per-token model of OpenAI.
Table: Economic Comparison for Enterprise
| Cost Factor | GPT Image 1.5 (API) | Nano Banana Pro (Vertex AI) |
|---|---|---|
| Pricing Model | Token-Based (Input/Output) | Per-Image / Resolution Tier |
| Est. Cost (Standard) | ~$0.04 - $0.17 / image | ~$0.134 / image |
| Est. Cost (4K) | N/A (Upscaling required) | ~$0.24 / image |
| Batch Discount | N/A (Cache discounts only) | Yes (~50% discount) |
| | Volume Incentive | Caching reduces repetitive prompt cost | Batching reduces large job cost |
Insight: GPT Image 1.5's pricing favors "agentic" loops where an AI might perform many small, low-res drafting steps before finalizing. Nano Banana Pro's pricing favors "final production," where a single high-cost, high-res generation is the desired output.
8. Community Sentiment and Cultural Impact
The reception of these models has been polarized, reflecting the different priorities of the AI community.
8.1. The "Realism" Debate
On platforms like Reddit (r/Singularity, r/StableDiffusion) and X (Twitter), a consensus has emerged regarding the "look" of the models.
-
Pro-Google Sentiment: Users frequently cite Nano Banana Pro as the "King of Realism." The ability to generate images that look like "crappy phone photos" is paradoxically its greatest strength. Users appreciate that it doesn't force a "cinematic" look unless asked. The "Chibi 3D Diorama" trend—where users turned themselves into cute, toy-like figures—showcased the model's ability to handle specific material textures (plastic, matte PVC) and lighting (internal glow) with delightful accuracy.
-
Pro-OpenAI Sentiment: Users praise GPT Image 1.5 for its reliability. The "It just works" factor is significant. While some criticize the "glossy" look, others appreciate that the model rarely produces "nightmare fuel" (distorted limbs, botched faces) due to its heavy safety fine-tuning. It is seen as the "safe" choice for business presentations.
8.2. The "Refusal" Frustration
A major point of contention for Nano Banana Pro is its aggressive safety filtering. Users report high "refusal rates" for benign prompts, often due to over-sensitive triggers regarding public figures or "unsafe" concepts. This "nanny filter" is a frequent complaint that drives users back to OpenAI or open-source models like Flux, despite Google's superior image quality.
8.3. Leaderboard Wars
While user anecdotes favor Google for realism, the LMArena benchmarks tell a story of OpenAI dominance in "steerability." GPT Image 1.5 debuted at #1 on the text-to-image leaderboard with an ELO of 1277, dethroning Nano Banana Pro (1235). This discrepancy highlights the difference between "blind preference" (where users often pick the image that best matches the prompt logic) and "aesthetic preference" (where users pick the image that looks most real).
9. Future Outlook: The Convergence of Video
The rivalry in static image generation is merely the prelude to the war for video. Both companies are using these models as foundational layers for temporal media.
-
Google: Nano Banana Pro is explicitly linked to Veo 3.1, Google's video generation model. The ability to generate consistent characters and assets in Nano Banana Pro is the first step in a workflow that ends with a generated video clip in Veo.
-
OpenAI: GPT Image 1.5’s "verbs" (add, subtract, blend) are the semantic primitives for video editing. If a model can "add a car" to a static image consistently, it is one step away from "adding a moving car" to a video stream.
As we move deeper into 2026, we can expect the distinction between "image model" and "video model" to collapse. The "Code Red" has not ended; it has simply moved to a higher frame rate.
10. Conclusion and Recommendations
The choice between GPT Image 1.5 and Nano Banana Pro is not a binary selection of "better" or "worse," but a strategic decision based on the desired utility function.
Choose GPT Image 1.5 If:
- Logic is Paramount: Your use case involves complex layouts, grids, or strict logical constraints (e.g., UI mockups, diagrams).
- Workflow Speed: You require a real-time, conversational iteration loop where you can "talk" the image into existence.
- Developer Flexibility: You are building an application that benefits from granular token-based pricing and integration with the OpenAI API stack.
Choose Nano Banana Pro If:
- Realism is King: You need photorealistic assets that mimic the imperfections of optical photography (e.g., marketing lifestyle shots).
- Resolution Matters: You require native 4K output for print or high-fidelity digital displays.
- Brand Consistency: You need to maintain strict character or style consistency across massive batches of images using reference fusion.
- Ecosystem Integration: Your organization is already embedded in Google Workspace and can leverage the seamless integration with Slides and Vids.
In the final analysis, Nano Banana Pro wins the battle for the "eye," delivering superior visual fidelity and texture. GPT Image 1.5 wins the battle for the "mind," delivering superior logic, instruction following, and workflow velocity. The "Code Red" era has produced not one winner, but two distinct apex predators in the visual ecosystem.